In the last post, I introduced the U-Net model for segmenting salt depots in seismic images. This time, we will see how to improve the model by data augmentation and especially test time augmentation (TTA). You will learn how to use data augmentation with segmentation masks and what test time augmentation is and how to use it in keras. For convenience we reuse a lot of functions from the last post.
import numpy as np
import matplotlib.pyplot as plt
plt.style.use("ggplot")
%matplotlib inline
from skimage.io import imread, imshow, concatenate_images
from skimage.transform import resize
from skimage.morphology import label
from sklearn.model_selection import train_test_split
import tensorflow as tf
from keras.models import Model, load_model
from keras.layers import Input, BatchNormalization, Activation, Dense, Dropout
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.layers.merge import concatenate, add
from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau
from keras.optimizers import Adam, Nadam
from keras.preprocessing.image import ImageDataGenerator, array_to_img, img_to_array, load_img
Using TensorFlow backend.
# Set some parameters
im_width = 128
im_height = 128
border = 5
path_train = '../input/train/'
path_test = '../input/test/'
Load the images
X, y = get_data(path_train, train=True)
X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.15, random_state=2018)
Getting and resizing images ...
A Jupyter Widget
Done!
What is data augmentation?
input_img = Input((im_height, im_width, 1), name='img')
model = get_unet(input_img, n_filters=16, dropout=0., batchnorm=True)
model.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=["accuracy"])
Since using a lot of data is critical to train deep neural networks data augmentation is a way to multiply your training data. This is especially important if not much data is available. So we just apply some transformations randomly to the input images and train the model on the augmented images. Common transformations include flips, distortions and rotations. In this competition only flips seem to work for me. Since we have a label for each pixel, we also need to apply the same transformation also to the labels, in this case the segmentation masks. I’ll show you how to do this in keras.
data_gen_args = dict(horizontal_flip=True,
vertical_flip=True)
image_datagen = ImageDataGenerator(**data_gen_args)
mask_datagen = ImageDataGenerator(**data_gen_args)
seed = 2018
bs = 32
image_generator = image_datagen.flow(X_train, seed=seed, batch_size=bs, shuffle=True)
mask_generator = mask_datagen.flow(y_train, seed=seed, batch_size=bs, shuffle=True)
# Just zip the two generators to get a generator that provides augmented images and masks at the same time
train_generator = zip(image_generator, mask_generator)
It is important to use the same seed for both generators. If you don’t know about data generators in keras, read about them here. They are quite useful! Now we can train the model. We use some callbacks to save the model while training, lower the learning rate if the validation loss plateaus and perform early stopping.
callbacks = [
EarlyStopping(patience=10, verbose=1),
ReduceLROnPlateau(factor=0.1, patience=3, min_lr=0.000001, verbose=1),
ModelCheckpoint('model-tgs-salt.h5', verbose=1, save_best_only=True, save_weights_only=True)
]
results = model.fit_generator(train_generator, steps_per_epoch=(len(X_train) // bs), epochs=100, callbacks=callbacks,
validation_data=(X_valid, y_valid))
Epoch 1/100
106/106 [==============================] - 34s 319ms/step - loss: 0.4147 - acc: 0.8295 - val_loss: 0.8609 - val_acc: 0.7923
Epoch 00001: val_loss improved from inf to 0.86095, saving model to model-tgs-salt.h5
Epoch 2/100
106/106 [==============================] - 27s 258ms/step - loss: 0.3128 - acc: 0.8760 - val_loss: 0.5690 - val_acc: 0.7663
Epoch 00002: val_loss improved from 0.86095 to 0.56899, saving model to model-tgs-salt.h5
Epoch 3/100
106/106 [==============================] - 27s 255ms/step - loss: 0.2917 - acc: 0.8792 - val_loss: 0.3502 - val_acc: 0.8738
Epoch 00003: val_loss improved from 0.56899 to 0.35023, saving model to model-tgs-salt.h5
Epoch 4/100
106/106 [==============================] - 27s 254ms/step - loss: 0.2703 - acc: 0.8870 - val_loss: 0.3358 - val_acc: 0.8876
Epoch 00004: val_loss improved from 0.35023 to 0.33578, saving model to model-tgs-salt.h5
Epoch 5/100
106/106 [==============================] - 27s 254ms/step - loss: 0.2560 - acc: 0.8927 - val_loss: 0.2577 - val_acc: 0.8922
Epoch 00005: val_loss improved from 0.33578 to 0.25773, saving model to model-tgs-salt.h5
Epoch 6/100
106/106 [==============================] - 27s 255ms/step - loss: 0.2378 - acc: 0.8968 - val_loss: 0.3107 - val_acc: 0.8895
Epoch 00006: val_loss did not improve
Epoch 7/100
106/106 [==============================] - 27s 255ms/step - loss: 0.2369 - acc: 0.9014 - val_loss: 0.2577 - val_acc: 0.9055
Epoch 00007: val_loss did not improve
Epoch 8/100
106/106 [==============================] - 27s 255ms/step - loss: 0.2144 - acc: 0.9080 - val_loss: 0.2891 - val_acc: 0.8844
Epoch 00008: ReduceLROnPlateau reducing learning rate to 0.00010000000474974513.
Epoch 00008: val_loss did not improve
Epoch 9/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1967 - acc: 0.9166 - val_loss: 0.1812 - val_acc: 0.9223
Epoch 00009: val_loss improved from 0.25773 to 0.18125, saving model to model-tgs-salt.h5
Epoch 10/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1914 - acc: 0.9172 - val_loss: 0.1840 - val_acc: 0.9203
Epoch 00010: val_loss did not improve
Epoch 11/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1848 - acc: 0.9203 - val_loss: 0.1778 - val_acc: 0.9239
Epoch 00011: val_loss improved from 0.18125 to 0.17783, saving model to model-tgs-salt.h5
Epoch 12/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1752 - acc: 0.9228 - val_loss: 0.1724 - val_acc: 0.9239
Epoch 00012: val_loss improved from 0.17783 to 0.17235, saving model to model-tgs-salt.h5
Epoch 13/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1834 - acc: 0.9197 - val_loss: 0.1730 - val_acc: 0.9223
Epoch 00013: val_loss did not improve
Epoch 14/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1730 - acc: 0.9239 - val_loss: 0.1715 - val_acc: 0.9231
Epoch 00014: val_loss improved from 0.17235 to 0.17146, saving model to model-tgs-salt.h5
Epoch 15/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1715 - acc: 0.9242 - val_loss: 0.1659 - val_acc: 0.9245
Epoch 00015: val_loss improved from 0.17146 to 0.16590, saving model to model-tgs-salt.h5
Epoch 16/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1734 - acc: 0.9247 - val_loss: 0.1631 - val_acc: 0.9260
Epoch 00016: val_loss improved from 0.16590 to 0.16310, saving model to model-tgs-salt.h5
Epoch 17/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1703 - acc: 0.9260 - val_loss: 0.1646 - val_acc: 0.9269
Epoch 00017: val_loss did not improve
Epoch 18/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1723 - acc: 0.9243 - val_loss: 0.1643 - val_acc: 0.9269
Epoch 00018: val_loss did not improve
Epoch 19/100
106/106 [==============================] - 27s 256ms/step - loss: 0.1592 - acc: 0.9299 - val_loss: 0.1576 - val_acc: 0.9287
Epoch 00019: val_loss improved from 0.16310 to 0.15761, saving model to model-tgs-salt.h5
Epoch 20/100
106/106 [==============================] - 27s 256ms/step - loss: 0.1681 - acc: 0.9249 - val_loss: 0.1565 - val_acc: 0.9293
Epoch 00020: val_loss improved from 0.15761 to 0.15651, saving model to model-tgs-salt.h5
Epoch 21/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1621 - acc: 0.9286 - val_loss: 0.1527 - val_acc: 0.9319
Epoch 00021: val_loss improved from 0.15651 to 0.15270, saving model to model-tgs-salt.h5
Epoch 22/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1518 - acc: 0.9332 - val_loss: 0.1535 - val_acc: 0.9307
Epoch 00022: val_loss did not improve
Epoch 23/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1671 - acc: 0.9280 - val_loss: 0.1553 - val_acc: 0.9310
Epoch 00023: val_loss did not improve
Epoch 24/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1547 - acc: 0.9311 - val_loss: 0.1497 - val_acc: 0.9307
Epoch 00024: val_loss improved from 0.15270 to 0.14970, saving model to model-tgs-salt.h5
Epoch 25/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1633 - acc: 0.9286 - val_loss: 0.1482 - val_acc: 0.9331
Epoch 00025: val_loss improved from 0.14970 to 0.14819, saving model to model-tgs-salt.h5
Epoch 26/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1551 - acc: 0.9322 - val_loss: 0.1500 - val_acc: 0.9325
Epoch 00026: val_loss did not improve
Epoch 27/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1610 - acc: 0.9273 - val_loss: 0.1489 - val_acc: 0.9313
Epoch 00027: val_loss did not improve
Epoch 28/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1489 - acc: 0.9339 - val_loss: 0.1507 - val_acc: 0.9294
Epoch 00028: ReduceLROnPlateau reducing learning rate to 1.0000000474974514e-05.
Epoch 00028: val_loss did not improve
Epoch 29/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1434 - acc: 0.9355 - val_loss: 0.1461 - val_acc: 0.9321
Epoch 00029: val_loss improved from 0.14819 to 0.14612, saving model to model-tgs-salt.h5
Epoch 30/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1423 - acc: 0.9360 - val_loss: 0.1456 - val_acc: 0.9333
Epoch 00030: val_loss improved from 0.14612 to 0.14562, saving model to model-tgs-salt.h5
Epoch 31/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1409 - acc: 0.9358 - val_loss: 0.1452 - val_acc: 0.9331
Epoch 00031: val_loss improved from 0.14562 to 0.14521, saving model to model-tgs-salt.h5
Epoch 32/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1526 - acc: 0.9318 - val_loss: 0.1451 - val_acc: 0.9336
Epoch 00032: val_loss improved from 0.14521 to 0.14515, saving model to model-tgs-salt.h5
Epoch 33/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1431 - acc: 0.9361 - val_loss: 0.1439 - val_acc: 0.9334
Epoch 00033: val_loss improved from 0.14515 to 0.14393, saving model to model-tgs-salt.h5
Epoch 34/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1448 - acc: 0.9360 - val_loss: 0.1447 - val_acc: 0.9342
Epoch 00034: val_loss did not improve
Epoch 35/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1388 - acc: 0.9367 - val_loss: 0.1442 - val_acc: 0.9336
Epoch 00035: val_loss did not improve
Epoch 36/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1454 - acc: 0.9340 - val_loss: 0.1435 - val_acc: 0.9340
Epoch 00036: val_loss improved from 0.14393 to 0.14346, saving model to model-tgs-salt.h5
Epoch 37/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1442 - acc: 0.9354 - val_loss: 0.1434 - val_acc: 0.9339
Epoch 00037: val_loss improved from 0.14346 to 0.14341, saving model to model-tgs-salt.h5
Epoch 38/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1443 - acc: 0.9344 - val_loss: 0.1438 - val_acc: 0.9336
Epoch 00038: val_loss did not improve
Epoch 39/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1458 - acc: 0.9331 - val_loss: 0.1438 - val_acc: 0.9330
Epoch 00039: ReduceLROnPlateau reducing learning rate to 1.0000000656873453e-06.
Epoch 00039: val_loss did not improve
Epoch 40/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1459 - acc: 0.9348 - val_loss: 0.1436 - val_acc: 0.9335
Epoch 00040: val_loss did not improve
Epoch 41/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1383 - acc: 0.9370 - val_loss: 0.1433 - val_acc: 0.9333
Epoch 00041: val_loss improved from 0.14341 to 0.14331, saving model to model-tgs-salt.h5
Epoch 42/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1440 - acc: 0.9352 - val_loss: 0.1432 - val_acc: 0.9335
Epoch 00042: val_loss improved from 0.14331 to 0.14319, saving model to model-tgs-salt.h5
Epoch 43/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1436 - acc: 0.9362 - val_loss: 0.1433 - val_acc: 0.9336
Epoch 00043: val_loss did not improve
Epoch 44/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1430 - acc: 0.9347 - val_loss: 0.1431 - val_acc: 0.9338
Epoch 00044: val_loss improved from 0.14319 to 0.14312, saving model to model-tgs-salt.h5
Epoch 45/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1344 - acc: 0.9384 - val_loss: 0.1433 - val_acc: 0.9338
Epoch 00045: ReduceLROnPlateau reducing learning rate to 1e-06.
Epoch 00045: val_loss did not improve
Epoch 46/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1561 - acc: 0.9306 - val_loss: 0.1432 - val_acc: 0.9338
Epoch 00046: val_loss did not improve
Epoch 47/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1423 - acc: 0.9361 - val_loss: 0.1431 - val_acc: 0.9338
Epoch 00047: val_loss improved from 0.14312 to 0.14306, saving model to model-tgs-salt.h5
Epoch 48/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1423 - acc: 0.9355 - val_loss: 0.1429 - val_acc: 0.9338
Epoch 00048: val_loss improved from 0.14306 to 0.14289, saving model to model-tgs-salt.h5
Epoch 49/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1468 - acc: 0.9349 - val_loss: 0.1431 - val_acc: 0.9337
Epoch 00049: val_loss did not improve
Epoch 50/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1405 - acc: 0.9361 - val_loss: 0.1428 - val_acc: 0.9337
Epoch 00050: val_loss improved from 0.14289 to 0.14285, saving model to model-tgs-salt.h5
Epoch 51/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1470 - acc: 0.9344 - val_loss: 0.1430 - val_acc: 0.9337
Epoch 00051: val_loss did not improve
Epoch 52/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1389 - acc: 0.9373 - val_loss: 0.1434 - val_acc: 0.9338
Epoch 00052: val_loss did not improve
Epoch 53/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1445 - acc: 0.9345 - val_loss: 0.1433 - val_acc: 0.9337
Epoch 00053: val_loss did not improve
Epoch 54/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1366 - acc: 0.9387 - val_loss: 0.1432 - val_acc: 0.9338
Epoch 00054: val_loss did not improve
Epoch 55/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1456 - acc: 0.9355 - val_loss: 0.1433 - val_acc: 0.9338
Epoch 00055: val_loss did not improve
Epoch 56/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1468 - acc: 0.9351 - val_loss: 0.1433 - val_acc: 0.9338
Epoch 00056: val_loss did not improve
Epoch 57/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1353 - acc: 0.9390 - val_loss: 0.1435 - val_acc: 0.9338
Epoch 00057: val_loss did not improve
Epoch 58/100
106/106 [==============================] - 27s 254ms/step - loss: 0.1498 - acc: 0.9345 - val_loss: 0.1433 - val_acc: 0.9338
Epoch 00058: val_loss did not improve
Epoch 59/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1487 - acc: 0.9346 - val_loss: 0.1434 - val_acc: 0.9339
Epoch 00059: val_loss did not improve
Epoch 60/100
106/106 [==============================] - 27s 255ms/step - loss: 0.1418 - acc: 0.9358 - val_loss: 0.1436 - val_acc: 0.9339
Epoch 00060: val_loss did not improve
Epoch 00060: early stopping
plt.figure(figsize=(8, 8))
plt.title("Learning curve")
plt.plot(results.history["loss"], label="loss")
plt.plot(results.history["val_loss"], label="val_loss")
plt.plot( np.argmin(results.history["val_loss"]), np.min(results.history["val_loss"]), marker="x", color="r", label="best model")
plt.xlabel("Epochs")
plt.ylabel("log_loss")
plt.legend();
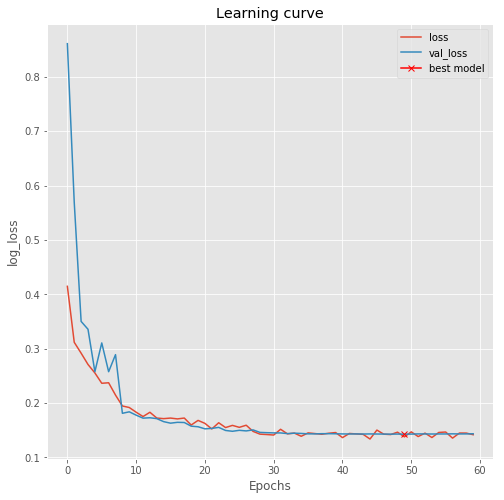
Inference with the model
Now we can load the best model we saved and look at some predictions.
# Load best model
model.load_weights('model-tgs-salt.h5')
# Evaluate on validation set (this must be equals to the best log_loss)
model.evaluate(X_valid, y_valid, verbose=1)
600/600 [==============================] - 2s 3ms/step
[0.1428457408150037, 0.9336776733398438]
# Predict on train, val and test
preds_train = model.predict(X_train, verbose=1)
preds_val = model.predict(X_valid, verbose=1)
3400/3400 [==============================] - 9s 3ms/step
600/600 [==============================] - 2s 3ms/step
Test time augmentation
Test time augmentation is a common way to improve the accuracy of image classifiers especially in the case of deep learning. We change the image we want to predict in some ways, get the predictions for all of these images and average the predictions. The intuition behind this is that even if the test image is not too easy to make a prediction, the transformations change it such that the model has higher chances of capturing the target shape and predicting accordingly. In general you would try a lot of different transformations, but in this case only flips seems to work. So we do horizontal and vertical flips. This means we get four different images per test image. Let’s see how they look like.
def show_flipped_images(x):
fig, ax = plt.subplots(1, 4, figsize=(20, 10))
ax[0].imshow(x[:,:,0], cmap='seismic')
ax[0].set_title('original')
ax[1].imshow(np.fliplr(x[:,:,0]), cmap='seismic')
ax[2].imshow(np.flipud(x[:,:,0]), cmap='seismic')
ax[3].imshow(np.fliplr(np.flipud(x[:,:,0])), cmap='seismic')
show_flipped_images(X_train[14])
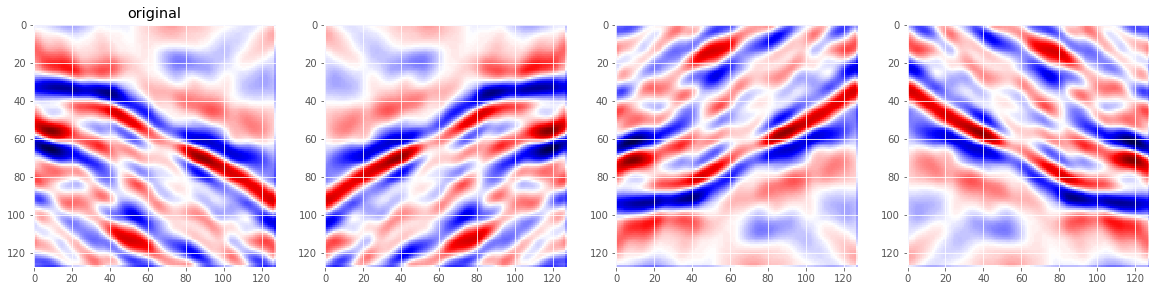
I wrote a little keras wrapper to do TTA with keras models conviniently. You can get it here: https://github.com/tsterbak/keras_tta We just wrap our trained model and use the wrapped model to predict on the validation images.
tta_model = TTA_ModelWrapper(model)
preds_val_tta = tta_model.predict(X_valid)
preds_train_tta = tta_model.predict(X_train)
A Jupyter Widget
A Jupyter Widget
An important step we skip here is to select an appropriate threshold for the model. This is normally done by optimizing the threshold on a holdout set. Let’s look at some predictions.
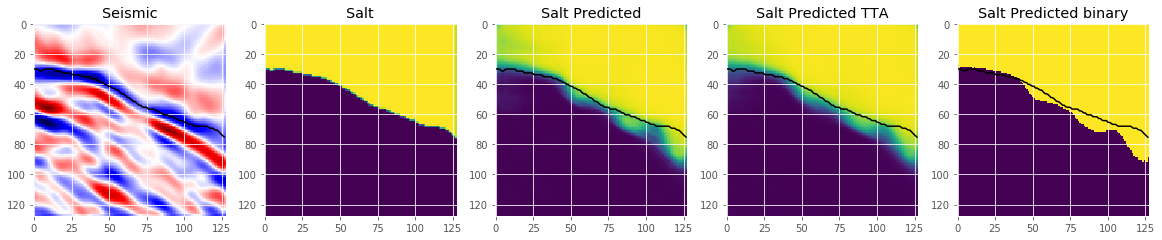
def plot_sample(X, y, preds, preds_tta, binary_preds, ix=None):
if ix is None:
ix = random.randint(0, len(X))
has_mask = y[ix].max() > 0
fig, ax = plt.subplots(1, 5, figsize=(20, 10))
ax[0].imshow(X[ix, ..., 0], cmap='seismic')
if has_mask:
ax[0].contour(y[ix].squeeze(), colors='k', levels=[0.5])
ax[0].set_title('Seismic')
ax[1].imshow(y[ix].squeeze())
ax[1].set_title('Salt')
ax[2].imshow(preds[ix].squeeze(), vmin=0, vmax=1)
if has_mask:
ax[2].contour(y[ix].squeeze(), colors='k', levels=[0.5])
ax[2].set_title('Salt Predicted')
ax[3].imshow(preds_tta[ix].squeeze(), vmin=0, vmax=1)
if has_mask:
ax[3].contour(y[ix].squeeze(), colors='k', levels=[0.5])
ax[3].set_title('Salt Predicted TTA')
ax[4].imshow(binary_preds[ix].squeeze(), vmin=0, vmax=1)
if has_mask:
ax[4].contour(y[ix].squeeze(), colors='k', levels=[0.5])
ax[4].set_title('Salt Predicted binary');
# Check if training data looks all right
plot_sample(X_train, y_train, preds_train, preds_train_tta, preds_train_tta>0.5, ix=14)
# Check if valid data looks all right
plot_sample(X_valid, y_valid, preds_val, preds_val_tta, preds_val_tta>0.5, ix=19)
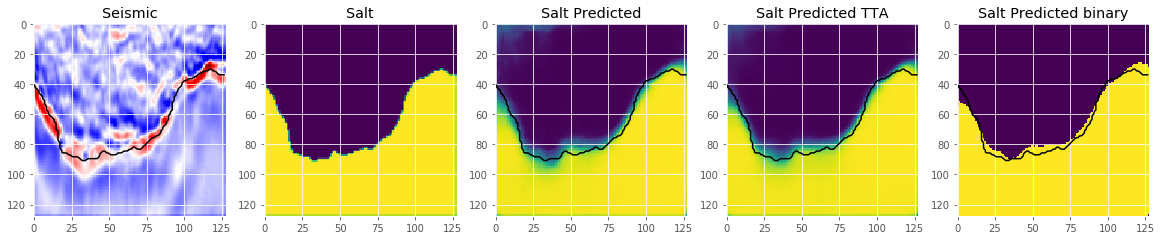
We see, that this improves the results quite a bit. Try submitting the predictions of this model to the competition. After picking an appropriate threshold you should get a leaderboard score of around . This is a nice improvement of around 6%.
I hope you enjoyed this post and learned something. Looking forward to hear your experiences and see you in the competition.
